Publications
Highlights
(For a full list see below or go to Google Scholar)
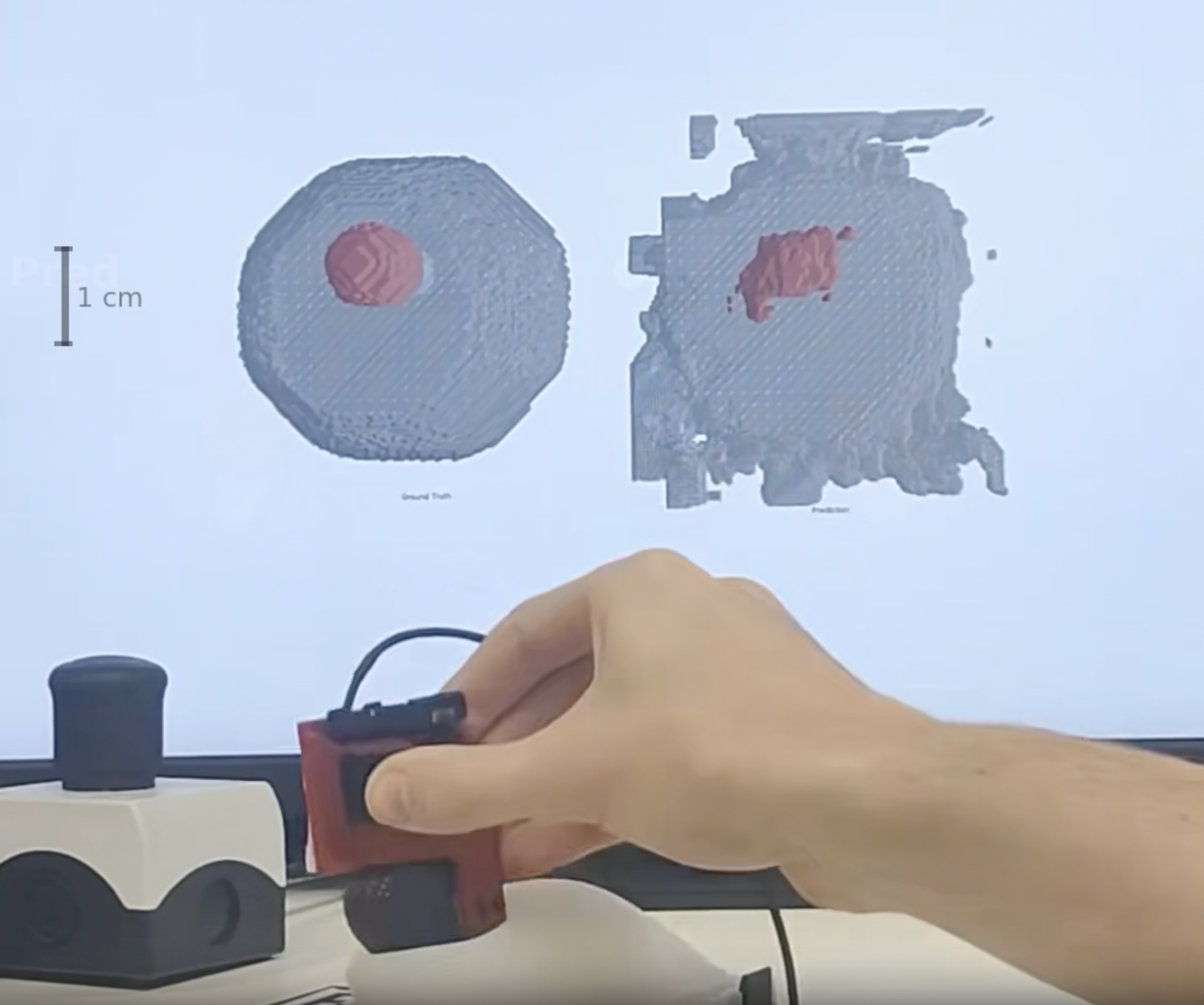
Reconstruct and visualize 3D structure of soft objects from artificial touch
Z. Rimon, E. Shafer, T. Tepper, D. Kozin, A. Malka, R. Holland, and A. Tamar
Robots: Science and Systems (RSS), 2026

A surprising method to improve generalization in imitation learning by reducing information from the demonstrator
E. Zisselman, M. Mutti, S. Francis-Meretzki, E. Shafer, and A. Tamar
Advances in Neural Information Processing Systems (NeurIPS), 2025
Best robotics paper award at ICML ExAIT Workshop

First method that learns how soft objects feel, and can image their internal structure
Z. Rimon, E. Shafer, T. Tepper, E. Shimron, and A. Tamar
Advances in Neural Information Processing Systems (NeurIPS), 2025

An object-centric video prediction model that can account for complex interactions between objects
T. Daniel and A. Tamar
Transactions on Machine Learning Research (TMLR), 2024
Train large models to control diverse behaviors using a new learning approach
G. Leibovich, G. Jacob, O. Avner, G. Novik, and A. Tamar
International Conference on Machine Learning (ICML), 2023
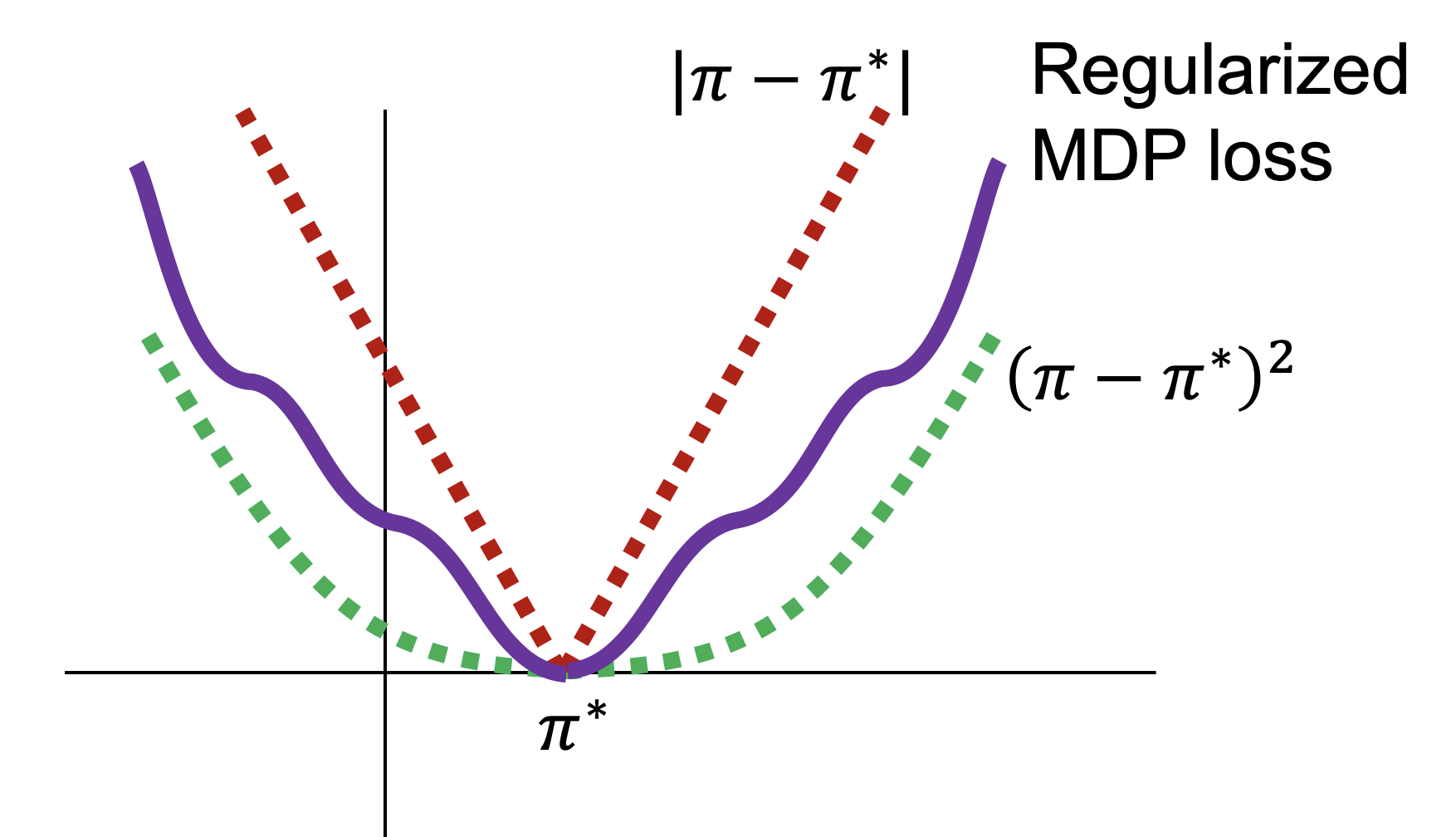
We develop PAC bounds for Bayesian RL (meta-RL). A key underlying result is showing algorithmic stability for regularized MDPs.
A. Tamar, D. Soudry, E. Zisselman.
Oral
We formulate a Bayesian view of offline meta RL, and learn how to effectively explore in a new task.
R. Dorfman, I. Shenfeld, and A. Tamar.
Advances in Neural Information Processing Systems (NeurIPS), 2021.
We identify a connection between the value iteration algorithm and CNNs, and use it to develop neural networks with a built in planning module.
A. Tamar, Y. Wu, G. Thomas, S. Levine, and P. Abbeel.
Advances in Neural Information Processing Systems (NeurIPS), pages 2154–2162, 2016.
Best paper award
Full List
Pre-prints
-
Towards Deployable RL–What’s Broken with RL Research and a Potential Fix
S. Mannor and A. Tamar
arXiv preprint arXiv:2301.01320, 2023 -
Goal-Conditioned Supervised Learning with Sub-Goal Prediction
T. Jurgenson and A. Tamar
arXiv preprint arXiv:2305.10171, 2023 -
Deep Variational Semi-Supervised Novelty Detection
T. Daniel, T. Kurutach, and A. Tamar.
arXiv:1911.04971 -
Safer Classification by Synthesis
W. Wang, A. Wang, A. Tamar, X. Chen, and P. Abbeel.
arXiv:1711.08534
Journal Papers / Books
-
Learning to Flow (Between Datacenters)
Y. Perry, S. Kandula, I. Menache, M. Schapira, and A. Tamar
Communications of the ACM, 2026 -
Reinforcement Learning: Foundations
S. Mannor, Y. Mansour, and A. Tamar
Cambridge University Press, forthcoming Summer 2026 -
DDLP: Unsupervised Object-Centric Video Prediction with Deep Dynamic Latent Particles
T. Daniel and A. Tamar
Transactions on Machine Learning Research (TMLR), 2024 -
Revealing principles of autonomous thermal soaring in windy conditions using vulture-inspired deep reinforcement-learning
Y. Flato, R. Harel, A. Tamar, R. Nathan, and T. Beatus
Nature Communications, 2024 -
Sequential decision making with coherent risk
A. Tamar, Y. Chow, M. Ghavamzadeh, and S. Mannor.
IEEE Transactions on Automatic Control, 62(7):3323–3338, 2017. -
Learning the variance of the reward-to-go
A. Tamar, D. Di Castro, and S. Mannor.
Journal of Machine Learning Research, 17(13):1–36, 2016. -
Bayesian reinforcement learning: A survey
M. Ghavamzadeh, S. Mannor, J. Pineau, and A. Tamar.
Foundations and Trends in Machine Learning, 8(5-6):359–483, 2015. -
Integrating a partial model into model free reinforcement learning
A. Tamar, D. Di Castro, and R. Meir.
Journal of Machine Learning Research, 13:1927–1966, 2012.
Conference Papers
-
More with LESS: Local Scene Representations for Tactile Imaging
Z. Rimon, E. Shafer, T. Tepper, D. Kozin, A. Malka, R. Holland, and A. Tamar
Robots: Science and Systems (RSS), 2026 -
Temporal Difference Calibration in Sequential Tasks: Application to Vision-Language-Action Models
S. Francis-Meretzki, M. Mutti, Y. Romano, and A. Tamar
International Conference on Machine Learning (ICML), 2026 -
MAD-DAG: Protecting Blockchain Consensus from MEV
R. Bar-Zur, A. Tamar, and I. Eyal
IEEE S&P, 2026 -
Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling
T. Daniel, C. Qi, D. Haramati, A. Zadeh, C. Li, A. Tamar, D. Pathak, and D. Held
International Conference on Learning Representations (ICLR), 2026 Oral presentation -
Probing in the Dark: State Entropy Maximization for POMDPs
Y. Ashlag, M. Mutti, A. Tamar, and K. Yehuda Levy
International Conference on Learning Representations (ICLR), 2026 -
Hierarchical Entity-centric Reinforcement Learning with Factored Subgoal Diffusion
D. Haramati, C. Qi, T. Daniel, A. Zhang, A. Tamar, and G. Konidaris
International Conference on Learning Representations (ICLR), 2026 -
Blindfolded Experts Generalize Better: Insights from Robotic Manipulation and Videogames
E. Zisselman, M. Mutti, S. Francis-Meretzki, E. Shafer, and A. Tamar
Advances in Neural Information Processing Systems (NeurIPS), 2025 Best robotics paper award at ICML ExAIT Workshop -
Toward Artificial Palpation: Representation Learning of Touch on Soft Bodies
Z. Rimon, E. Shafer, T. Tepper, E. Shimron, and A. Tamar
Advances in Neural Information Processing Systems (NeurIPS), 2025 -
A Classification View on Meta Learning Bandits
M. Mutti, J. Kwon, S. Mannor, and A. Tamar
International Conference on Machine Learning (ICML), 2025 -
EC-Diffuser: Multi-Object Manipulation via Entity-Centric Behavior Generation
C. Qi, D. Haramati, T. Daniel, A. Tamar, and A. Zhang
International Conference on Learning Representations (ICLR), 2025 -
From Configuration-Space Clearance to Feature-Space Margin: Sample Complexity in Learning-Based Collision Detection
S. Tubul, A. Tamar, K. Solovey, and O. Salzman
IEEE International Conference on Robotics and Automation (ICRA), 2025 -
A Bayesian Approach to Online Planning
N. Greshler, D. Ben Eli, C. Rabinovitz, L. Gispan, G. Guetta, G. Zohar, and A. Tamar
International Conference on Machine Learning (ICML), 2024 -
Test-Time Regret Minimization in Meta Reinforcement Learning
M. Mutti and A. Tamar
International Conference on Machine Learning (ICML), 2024 -
MAMBA: an Effective World Model Approach for Meta-Reinforcement Learning
Z. Rimon, T. Jurgenson, O. Krupnik, G. Adler, and A. Tamar
International Conference on Learning Representations (ICLR), 2024 -
Entity-Centric Reinforcement Learning for Object Manipulation from Pixels
D. Haramati, T. Daniel, and A. Tamar
International Conference on Learning Representations (ICLR), 2024 Spotlight -
Deep Bribe: Predicting the Rise of Bribery in Blockchain Mining with Deep RL
R. Bar-Zur, D. Dori, S. Vardi, I. Eyal, and A. Tamar
Deep Learning S&P Workshop 2023 (co-located with IEEE S&P) -
Explore to Generalize in Zero-Shot RL
E. Zisselman, I. Lavie, D. Soudry, and A. Tamar
Advances in Neural Information Processing Systems (NeurIPS), 2023 -
Hierarchical Planning for Rope Manipulation using Knot Theory and a Learned Inverse Model
M. Sudry, T. Jurgenson, A. Tamar, and E. Karpas
Conference on Robot Learning (CoRL), 2023, pages 1596-1609 -
Fine-Tuning Generative Models as an Inference Method for Robotic Tasks
O. Krupnik, E. Shafer, T. Jurgenson, and A. Tamar
Conference on Robot Learning (CoRL), 2023, pages 866-886 -
ContraBAR: Contrastive Bayes-Adaptive Deep RL
E. Choshen and A. Tamar
International Conference on Machine Learning (ICML), 2023. -
Learning Control by Iterative Inversion
G. Leibovich, G. Jacob, O. Avner, G. Novik, and A. Tamar
International Conference on Machine Learning (ICML), 2023 -
TGRL: Teacher Guided Reinforcement Learning Algorithm for POMDPs
I. Shenfeld, Z.-W. Hong, A. Tamar, and P. Agrawal
International Conference on Machine Learning (ICML), 2023. -
Online Tool Selection with Learned Grasp Prediction Models
K. Rohanimanesh, J. Metzger, W. Richards, and A. Tamar
IEEE International Conference on Robotics and Automation (ICRA), 2023. -
DOTE: Rethinking WAN Traffic Engineering
Y. Perry, F. Frujeri, C. Hoch, S. Kandula, I. Menache, M. Schapira, and A. Tamar
USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2023. Best paper award -
Meta Reinforcement Learning with Finite Training Tasks-a Density Estimation Approach
Z. Rimon, A. Tamar, and G. Adler.
Advances in Neural Information Processing Systems (NeurIPS), 2022. -
Unsupervised Image Representation Learning with Deep Latent Particles
T. Daniel and A. Tamar.
International Conference on Machine Learning (ICML), 2022 -
WeRLman: To Tackle Whale (Transactions), Go Deep (RL)
R. Bar-Zur, A. Abu-Hanna, I. Eyal, and A. Tamar.
IEEE Symposium on Security and Privacy (IEEE S&P 2023) -
Validate on Sim, Detect on Real – Model Selection for Domain Randomization
G. Leibovich, G. Jacob, S. Endrawis, G. Novik, and A. Tamar.
International Conference on Robotics and Automation (ICRA), 2022. -
Regularization Guarantees Generalization in Bayesian Reinforcement Learning through Algorithmic Stability
A. Tamar, D. Soudry, E. Zisselman.
AAAI, 2022. Oral -
Unsupervised Feature Learning for Manipulation with Contrastive Domain Randomization
C. Rabinovitz, N. Grupen, and A. Tamar.
International Conference on Robotics and Automation (ICRA), 2021. -
Efficient Self-Supervised Data Collection for Offline Robot Learning
S. Endrawis, G. Leibovich, G. Jacob, G. Novik, and A. Tamar.
International Conference on Robotics and Automation (ICRA), 2021. -
Soft-IntroVAE: Analyzing and Improving the Introspective Variational Autoencoder
T. Daniel and A. Tamar.
Computer Vision and Pattern Recognition (CVPR), 2021 Oral -
Online Safety Assurance for Learning-Augmented Systems
N. H. Rotman, M. Schapira, and A. Tamar.
ACM Workshop on Hot Topics in Networks (HotNets), 2020 -
Offline Meta Learning of Exploration
R. Dorfman, I. Shenfeld, and A. Tamar.
Advances in Neural Information Processing Systems (NeurIPS), 2021. -
Efficient MDP analysis for selfish-mining in blockchains
R. Bar Zur, I. Eyal, and A. Tamar.
ACM Advances in Financial Technologies (AFT), 2020 -
Hallucinative Topological Memory for Zero-Shot Visual Planning
K. Liu, T. Kurutach, C. Tung, P. Abbeel, and A. Tamar.
International Conference on Machine Learning (ICML), 2020 -
Sub-Goal Trees – a Framework for Goal-Based Reinforcement Learning
T. Jurgenson, O. Avner, E. Groshev, and A. Tamar.
International Conference on Machine Learning (ICML), 2020 -
Deep Residual Flow for Out of Distribution Detection
E. Zisselman, and A. Tamar.
Computer Vision and Pattern Recognition (CVPR), 2020 -
Harnessing reinforcement learning for neural motion planning
T. Jurgenson and A. Tamar.
Robotics: Science and Systems (RSS), 2019 -
Learning robotic manipulation through visual planning and acting
A. Wang, T. Kurutach, K. Liu, P. Abbeel, and A. Tamar.
Robotics: Science and Systems (RSS), 2019 -
Robust 2d assembly sequencing via geometric planning with learned costs
T. Geft, A. Tamar, K. Goldberg, and D. Halperin.
IEEE International Conference on Automation Science and Engineering (CASE), 2019 -
A Risk-Sensitive Finite-Time Reachability Approach for Safety of Stochastic Dynamic Systems
M. Chapman, J. Lacotte, A. Tamar, D. Lee, K. Smith, V. Cheng, J. Fisac, S. Jha, M. Pavone, and C. Tomlin.
American Control Conference, 2019 -
Multi agent reinforcement learning with multi-step generative models
O. Krupnik, I. Mordatch, and A. Tamar.
Conference on Robot Learning (CoRL), 2019. -
Internet congestion control via deep reinforcement learning
N. Jay, N. H. Rotman, P. Godfrey, M. Schapira, and A. Tamar.
International Conference on Machine Learning (ICML), 2019. -
Learning and planning with a semantic model
Y. Wu, Y. Wu, A. Tamar, S. Russell, G. Gkioxari, and Y. Tian.
International Conference on Computer Vision (ICCV), 2019. -
Distributional multivariate policy evaluation and exploration with the Bellman GAN
D. Freirich, T. Shimkin, R. Meir, and A. Tamar.
International Conference on Machine Learning (ICML), 2019. -
Constrained Policy Improvement for Efficient Reinforcement Learning
E. Sarafian, A. Tamar, and S. Kraus.
IJCAI-PRICAI 2020 -
Domain randomization for active pose estimation
X. Ren, J. Luo, E. Solowjow, J. Aparicio-Ojea, A. Gupta, A. Tamar, and P. Abbeel.
IEEE International Conference on Robotics and Automation (ICRA), 2019. -
Reinforcement learning on variable impedance controller for high-precision robotic assembly
J. Luo, E. Solowjow, C. Wen, J. Aparicio-Ojea, A. M. Agogino, A. Tamar, and P. Abbeel.
IEEE International Conference on Robotics and Automation (ICRA), 2019. -
Learning plannable representations with Causal InfoGAN
T. Kurutach, A. Tamar, G. Yang, S. Russell, and P. Abbeel.
Advances in Neural Information Processing Systems (NeurIPS), 2018. -
Learning generalized reactive policies using deep neural networks
E. Groshev, M. Goldstein, A. Tamar, S. Srivastava, and P. Abbeel.
International Conference on Automated Planning and Scheduling (ICAPS), 2018. -
Learning robotic assembly from CAD
G. Thomas, M. Chien, A. Tamar, J. Aparicio-Ojea, and P. Abbeel.
IEEE International Conference on Robotics and Automation (ICRA), 2018. Automation award track -
Imitation learning from visual data with multiple intentions
A. Tamar, K. Rohanimanesh, Y. Chow, C. Vigorito, B. Goodrich, M. Kahane, and D. Pridmore.
International Conference on Learning Representations (ICLR), 2018. -
Model-ensemble trust-region policy optimization
T. Kurutach, I. Clavera, Y. Duan, A. Tamar, and P. Abbeel.
International Conference on Learning Representations (ICLR), 2018. -
A machine learning approach to routing
A. Valadarsky, M. Schapira, D. Shahaf, and A. Tamar.
ACM Workshop on Hot Topics in Networks (HotNets), 2017. -
Multi-agent actor-critic for mixed cooperative-competitive environments
R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch.
Advances in Neural Information Processing Systems (NeurIPS), pages 6382–6393, 2017. -
Shallow updates for deep reinforcement learning
N. Levine, T. Zahavy, D. J. Mankowitz, A. Tamar, and S. Mannor.
Advances in Neural Information Processing Systems (NeurIPS), pages 3138–3148, 2017. -
Learning from the hindsight plan – episodic MPC improvement
A. Tamar, G. Thomas, T. Zhang, S. Levine, and P. Abbeel.
IEEE International Conference on Robotics and Automation (ICRA), pages 336–343, 2017. -
Constrained policy optimization
J. Achiam, D. Held, A. Tamar, and P. Abbeel.
International Conference on Machine Learning (ICML), pages 22–31, 2017. -
Value iteration networks
A. Tamar, Y. Wu, G. Thomas, S. Levine, and P. Abbeel.
Advances in Neural Information Processing Systems (NeurIPS), pages 2154–2162, 2016. Best paper award -
Generalized emphatic temporal difference learning: Bias-variance analysis
A. Hallak, A. Tamar, R. Munos, and S. Mannor.
AAAI, pages 1631–1637, 2016. -
Risk-sensitive and robust decision-making: a CVaR optimization approach
Y. Chow, A. Tamar, S. Mannor, and M. Pavone.
Advances in Neural Information Processing Systems (NeurIPS), pages 1522–1530, 2015. See https://arxiv.org/pdf/2304.12477.pdf for a discussion of an error in the optimality claim. -
Policy gradient for coherent risk measures
A. Tamar, Y. Chow, M. Ghavamzadeh, and S. Mannor.
Advances in Neural Information Processing Systems (NeurIPS), pages 1468–1476, 2015. -
Optimizing the CVaR via sampling
A. Tamar, Y. Glassner, and S. Mannor.
AAAI, pages 2993–2999, 2015. -
Scaling up robust MDPs using function approximation
A. Tamar, S. Mannor, and H. Xu.
International Conference on Machine Learning (ICML), pages 181–189, 2014. -
Temporal difference methods for the variance of the reward to go
A. Tamar, D. Di Castro, and S. Mannor.
International Conference on Machine Learning (ICML), pages 495–503, 2013. -
Policy gradients with variance related risk criteria
A. Tamar, D. Di Castro, and S. Mannor.
International Conference on Machine Learning (ICML), pages 387–396, 2012. -
Integrating partial model knowledge in model free RL algorithms
A. Tamar, D. D. Castro, and R. Meir.
International Conference on Machine Learning (ICML), pages 305–312, 2011.
Workshop Papers / Technical Reports
-
Situational awareness by risk-conscious skills
D. J. Mankowitz, A. Tamar, and S. Mannor.
arXiv preprint arXiv:1610.02847, 2016. -
Implicit temporal differences
A. Tamar, P. Toulis, S. Mannor, and E. M. Airoldi.
NeurIPS workshop on large-scale reinforcement learning and Markov decision problems, 2014. -
Variance adjusted actor critic algorithms
A. Tamar and S. Mannor.
arXiv preprint arXiv:1310.3697, 2013.